服务发现 - 需求与模式
服务发现是微服务架构中的核心基础设施,其本质是解决服务提供方与服务消费方之间的地址发现问题。在云时代,实例网络地址动态变化、数量弹性伸缩,传统的固定地址写死方式不再适用。本文深入分析了服务发现的两大核心驱动力(注册中心的健康检测与动态变更通知),对比介绍了客户端发现模式(Eureka、Consul Agent)和服务端发现模式(Nginx + Consul Template、Kubernetes Service),并分析了各种模式的优缺点及适用场景。
前言
从自成一体的单体应用到分布式应用,演进出了面向服务的架构。
服务发现的本质在于让服务之间发现彼此,这是服务提供方与服务消费方完成调用的前提。
在微服务架构下,无论是使用 Dubbo、Thrift、gRPC 这类标准的 RPC 实现进行通信,还是微服务所倡导的 RESTful 风格 API,服务发现都是一个避不开的话题。
需求
来举例一个简单的场景:
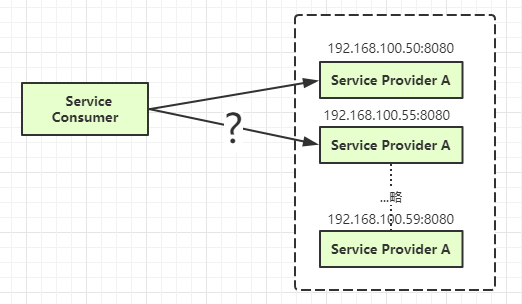
在固定数量、固定地址的情况下,Consumer 当然可以将服务提供者的地址写死到自己的应用内,按照随机或轮询的策略去访问服务提供者。
但在云时代,微服务架构下作为服务提供者的实例不一定运行在传统的物理机/虚拟机上:网络地址动态变化,实例数量还可能依据访问流量进行动态伸缩。
其中有两个最核心的问题:
-
消费者怎么找到服务提供者?——服务发现
-
在找到多个提供者实例后,选择哪个实例来调用?——负载均衡
可见,服务发现和负载均衡是分布式架构最根本的问题,同样也应该作为微服务的基础框架/组件。
方案
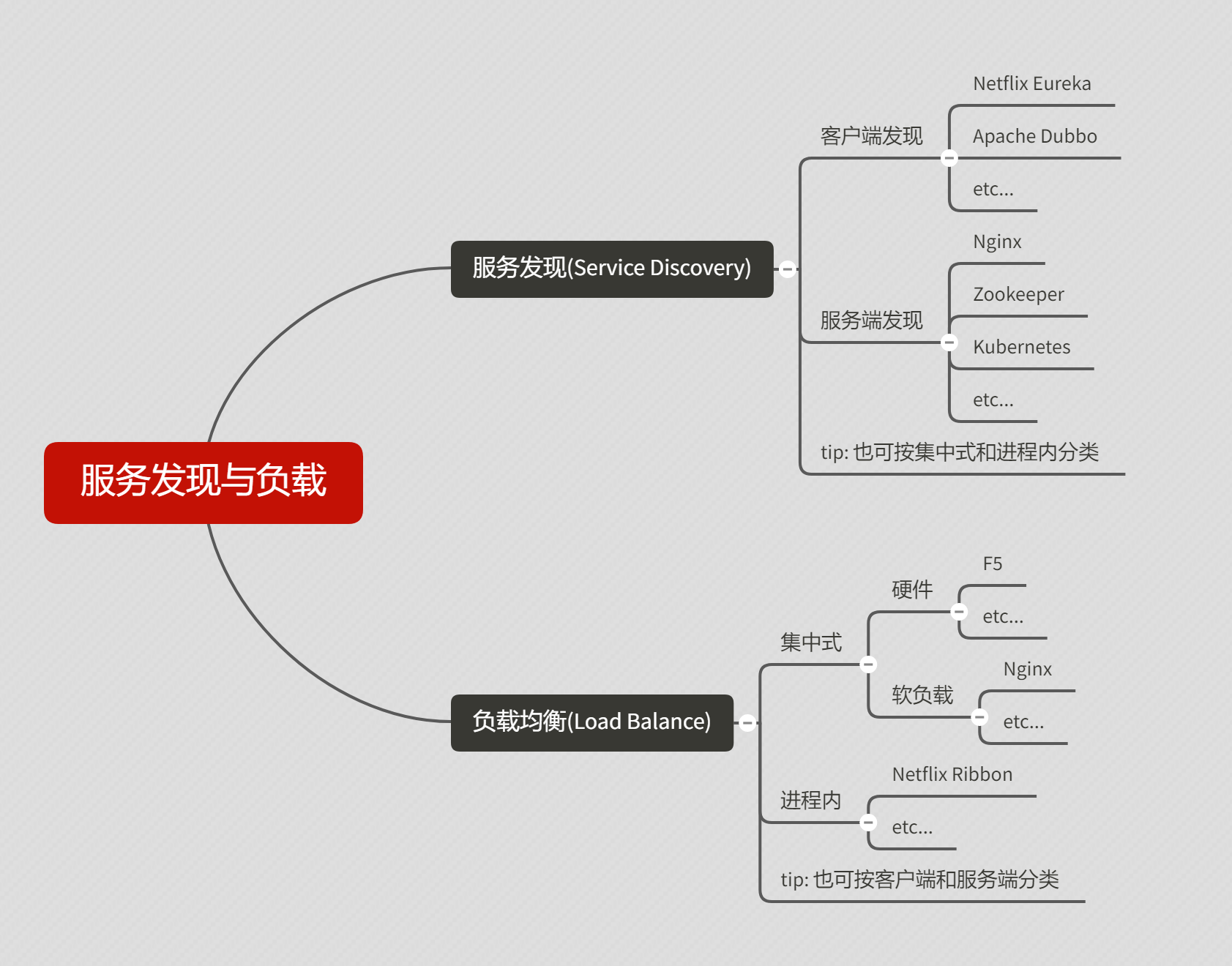
目前主要分为两类模式:客户端发现和服务端发现,也就是 client-side discovery pattern 和 server-side discovery pattern。
下面来介绍几种典型模式
- 集中式(传统)
- 客户端嵌入式(进程内)
- 主机独立进程
这几种模式都有业界较好的实践方案及开源组件
一:集中式
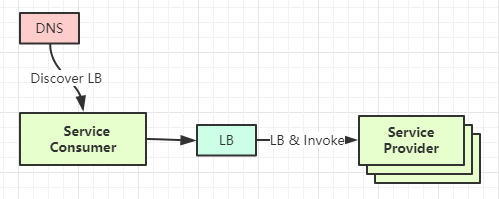
常用的独立 LB 可以使用硬件(F5)或软件(Nginx)等。
独立 LB 中需要手工配置服务列表地址,例如在 Nginx 中配置 upstream:
upstream service_provider {
server 192.168.100.100:8080;
server 192.168.100.101:8080;
}软负载的特点是配置灵活且易于扩展,还可以与硬件负载均衡器配合使用。硬件负载均衡器性能稳定、负载能力强。
例如 F5 下配置多个 Nginx 对其进行负载均衡,多个 Nginx 再对后台服务进行负载均衡。
这种方式重点提供的是 LB 能力,而“服务发现”通常是在 F5 或 Nginx 上通过配置来实现的,其功能对客户端来说是透明的。
这种模式相对简单, 在中小型公司中是很主流的方案
二:客户端嵌入式
也可以称为进程内代理
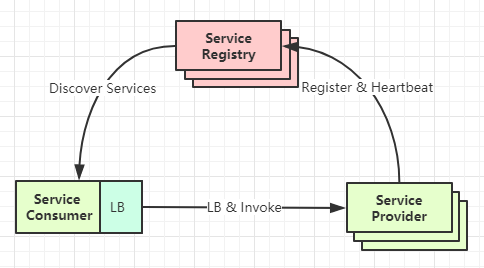
这种模式下,多了一个注册中心(服务注册表的概念),并且在客户端会集成一个类似 SDK 的东西:
- 对于服务提供者(Provider)来讲: 它需要注册到注册中心, 定期进行heartbeat检测
- 对于消费者(Consumer)来讲: 首先它能够从注册中心获取服务的实例, 也就是具备服务发现的能力
其次获取到服务列表后选择一个进行调用, 也就是具备负载均衡的能力
通常情况下, 整个过程可以做到自发现和自注册, 无需其它代理的介入
三:主机独立进程式
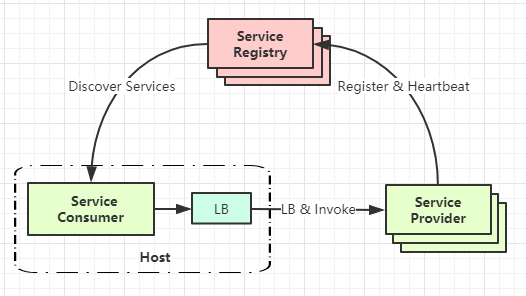
这种模式类似于上面一种,区别在于提供服务发现和负载均衡能力的组件没有嵌入每个客户端内,而是放在了同一主机下,可以理解为同一主机下的不同进程。
四:Other
实际中除了上述三种模式外,还有很多变种和折中方案,例如集中式代理结合服务注册中心实现服务的注册与发现。
以注册中心 Eureka Server 为例:它可以提供 UI/API 对接发布系统或手工注册,以及定期的健康检查;而无需在客户端集成 Eureka Client。集中式的 Proxy 需要同步注册中心中的服务地址。
总结
可以看到,以上三种最典型的方案中,相同点都是把具备服务发现和负载均衡能力的组件交给一个类似 Proxy 的角色来承担。
区别在于该角色所处的位置:放在客户端内还是客户端外,这也对应了两种分类:客户端发现与服务端发现、客户端负载与服务端负载。
通过以上几种方案的说明,我们可以理清它的分类:
结论与选型要点
- 关注“客户端是否感知后端拓扑变化”:感知则偏客户端发现/负载;不感知则偏服务端发现/负载。
- 关注“单点影响面”:集中式代理的单点影响面更大,通常要做多实例与高可用。
- 关注“语言栈与侵入性”:客户端嵌入式通常需要引入 SDK/Client 并适配语言栈;集中式代理对语言栈更无关。
- 关注“统一治理能力”:集中式代理更容易做统一鉴权、限流、路由等管控。
优劣性
每种方式都各有优劣, 没有绝对, 主要从这几方面来对比
可用性 & 性能
集中式方案中如果LB Proxy角色挂了, 那么影响的是所有客户端, 由于这种单点问题, 为了保证HA软负载通常需要部署多个, 好在Nginx无状态可水平扩展
进程内的方案如果客户端/Proxy挂了只对自己产生影响, 而主机独立进程的方案相对折中, 影响面仅为同一主机下的客户端
从图中能看出集中式的方案在服务的调用上会多一跳, 有一定的性能开销
语言栈
相较其它两种, 嵌入式的客户端需要针对客户端做集成和改造才能实现自注册和自发现, 说得难听点就是需要对服务有一定的侵入
并且这种改造需针对每种语言栈的服务定制
Netflix Eureka & Ribbon是该模式最典型的实现, 对于Java语言栈来说, 这一切都变得轻松.
微服务的异构旨在不同的数据库和语言栈, Eureka服务端提供了完善的REST API, 对于其它非Java语言栈只需实现自己语言对应的Eureka客户端程序, 就可以将非Java实现的服务纳入自己的服务治理体系
统一管控
从图中也能看出, 集中式方案可以做到集中式的访问控制, 而客户端进程内的模式则不易做到统一的管控, 主机独立进程的方式在两者之中
<br>对比
相信通过以上三种典型模式的了解, 对于业界常见的一些服务发现组件对应哪种模式应该很清楚了, 例如:
-
客户端发现: Netflix Eureka, Apache Dubbo, Motan
-
服务端发现: Nginx, Zookeeper, Kubernetes
而独立于主机进程的代理更像是Service Mesh的风格
| 模式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 集中式代理 | 运维简单, 集中治理, 语言栈无关 | 配置麻烦, 单点问题, 多一跳有性能开销 | 具备一定运维能力 |
| 客户端嵌入式代理 | 无单点问题, 性能较好 | 客户端复杂, 不易集中治理, 语言栈相关 | 语言栈统一 |
| 主机独立进程代理 | 以上两者折中 | 运维部署较复杂 | 具备一定运维能力 |