源码分析 - 服务发现组件 Netflix Eureka
Netflix Eureka 是 Spring Cloud 默认的服务注册与发现组件,本文结合 Eureka 架构图深入源码分析了其核心机制:服务生命周期包括 Register(服务注册)、Renew(心跳续约,默认30秒)、Cancel(主动下线)、Evict(服务端剔除过期服务,默认90秒)。详细剖析了 Eureka Server 的 MultiAwareInstanceRegistry、PeerAwareInstanceRegistryImpl,以及 Eureka Client 的 DiscoveryClient 源码实现,解释了为什么自我保护机制能防止网络分区故障时误删健康实例。
前言
结合 Netflix Eureka 架构图, 简单分析这一服务注册和服务发现组件的源码
目的
结合Netflix Eureka架构图
- 从源码解读Eureka架构图中服务生命周期
- Register: 服务注册
- Renew: 服务续约
- Cancel: 服务下线
- Evict: 服务剔除(Server 端)
- 从源码解读Eureka Peer Replicate过程
- 总结其一致性问题
说明
环境准备
源码获取: https://github.com/Netflix/eureka
项目结构如下:
eureka-client
eureka-client-archaius2
eureka-client-jersey2
eureka-core
eureka-core-jersey2
eureka-examples
eureka-resources
eureka-server
eureka-server-governator
eureka-test-utils
...本章节中只需要关注eureka-core和eureka-client两个模块
项目是纯Servlet应用, 使用Gradle构建, 这里我只是作为参照并没有构建, 在集成了Spring Cloud Netflix Eureka的项目中进行源码调试
- Spring Cloud: Finchley.SR2
- Spring Boot: 2.0.8.RELEASE
对应的Netflix Eureka版本为: v1.9.3
$ git checkout -b v1.9.3 v1.9.3在Spring Cloud集成Netflix Eureka的代码中, 还能看到两个与Eureka相关的包
- spring-cloud-netflix-eureka-server
- spring-cloud-netflix-eureka-client
这部分代码被称为胶水代码, 包含一些原生代码针对Spring项目的支持, 一些默认配置等
以及我们最熟悉的 Eureka Dashboard 界面, 都是由这部分代码完成
架构图
引用官方 wiki 中的架构图
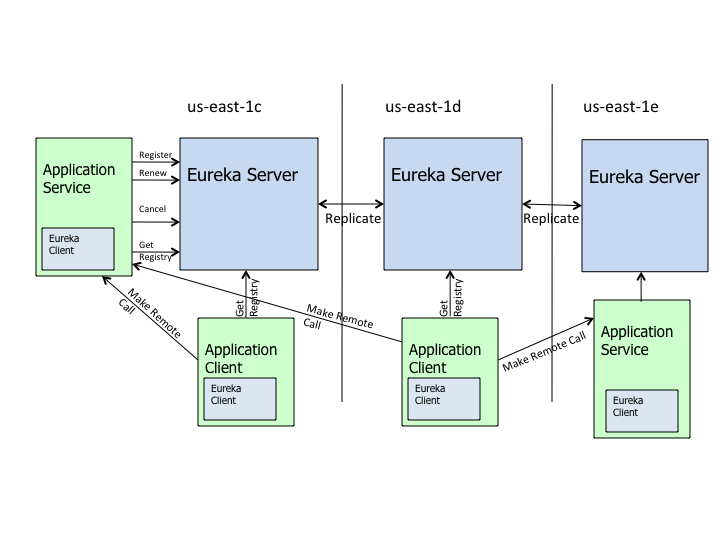
所以源码分析的角度就是上图中画直线的部分, 可以总结为两部分
- Eureka Server之间的Replicate
- Eureka Client 与 Eureka Server之间的Register, Renew, Cancel...
对于 Eureka Client, 我们还应该区分这样两个逻辑角色
- Service Provider: 服务提供者
- Service Consumer: 服务消费者
无论客户端发现还是服务端发现, 服务发现的本质在于能够让服务之间发现彼此, 这是服务提供方与服务消费方完成消费的前提, 对应架构图中的 Client 端之间的 Remote Call
源码解析
Eureka Server
启动入口
随着Eureka Server启动时的一行INFO日志Started Eureka Server
来到第一个入口点: EurekaServerInitializerConfiguration#start
@Configuration
public class EurekaServerInitializerConfiguration implements ServletContextAware, SmartLifecycle, Ordered {
// ...
@Override
public void start() {
new Thread(new Runnable() {
@Override
public void run() {
try {
//TODO: is this class even needed now?
eurekaServerBootstrap.contextInitialized(EurekaServerInitializerConfiguration.this.servletContext);
log.info("Started Eureka Server");
publish(new EurekaRegistryAvailableEvent(getEurekaServerConfig()));
EurekaServerInitializerConfiguration.this.running = true;
publish(new EurekaServerStartedEvent(getEurekaServerConfig()));
}
catch (Exception ex) {
// Help!
log.error("Could not initialize Eureka servlet context", ex);
}
}
}).start();
}
// ...
}^_^注释很有意思
这里看到了一个启动引导类EurekaServerBootstrap
public void contextInitialized(ServletContext context) {
try {
initEurekaEnvironment();
initEurekaServerContext();
context.setAttribute(EurekaServerContext.class.getName(), this.serverContext);
}
catch (Throwable e) {
log.error("Cannot bootstrap eureka server :", e);
throw new RuntimeException("Cannot bootstrap eureka server :", e);
}
}同样在eureka-core中也存在一个引导类EurekaBootStrap 这是Eureka Server的启动类, 代码与EurekaServerBootstrap基本类似
作用也基本相似, 都是完成eureka的初始化工作
不同的是EurekaBootStrap实现了Servlet API中的ServletContextListener接口
所以在容器启动时就会调用contextInitialized()方法完成init过程, 以及在终止时的contextDestroyed()
在这个引导类中, 还能够看到两个与配置相关的接口:
EurekaServerConfig eurekaServerConfig;EurekaClientConfig eurekaClientConfig;
没错, Eureka Server 和 Eureka Client的配置都在这里, 他们分别对应两个实现类:
- DefaultEurekaServerConfig implements EurekaServerConfig
- EurekaServerConfigBean implements EurekaServerConfig
一个是提供默认配置的类, 在netflix eureka源码中, 另一个在Spring Cloud Netflix的整合代码中, 是添加了@ConfigurationProperties的属性配置类, 前缀为eureka.server
很熟悉吧? 对应于我们平时在配置文件中配置的eureka.server.xxx.
Eureka Client端的EurekaClientConfig与之类似, 不说了
<br> #### Resources API从上面的架构图可以看到, Eureka Client需要向Eureka Server进行注册, 发送心跳更新租约, 获取注册信息等;
同时Eureka Server之间也要进行注册信息的同步
所以在Eureka Server中, 一定有对外提供REST API的入口, 这就是Resources中的内容, 你可以认为是控制器~
这部分代码在eureka-core中的com.netflix.eureka.resources中:
- ApplicationResource
- InstanceResource
- PeerReplicationResource
- etc...
通过类名上的@Path注解, 或是类名. 不难分辨他们分别代表什么资源
<br> #### Register&Renew&Cancel来看一个服务注册-register的API, 在ApplicationResource中
@POST
@Consumes({"application/json", "application/xml"})
public Response addInstance(InstanceInfo info,
@HeaderParam(PeerEurekaNode.HEADER_REPLICATION) String isReplication) {
// validate required fields...
// handle cases where clients may be registering with bad DataCenterInfo with missing data
// 省略...
registry.register(info, "true".equals(isReplication));
return Response.status(204).build(); // 204 to be backwards compatible
}我们可以模拟一个客户端调用看看: com.netflix.eureka.resources.ApplicationResource#getApplication
返回结果如下:
<application>
<name>CLOUDLINK-USER</name>
<instance>
<instanceId>192.168.153.1:cloudlink-user:8801</instanceId>
<hostName>localhost</hostName>
<app>CLOUDLINK-USER</app>
<ipAddr>192.168.153.1</ipAddr>
<status>UP</status>
<overriddenstatus>UNKNOWN</overriddenstatus>
<port enabled="true">8801</port>
<securePort enabled="false">443</securePort>
<countryId>1</countryId>
<dataCenterInfo class="com.netflix.appinfo.InstanceInfo$DefaultDataCenterInfo">
<name>MyOwn</name>
</dataCenterInfo>
<leaseInfo>
<renewalIntervalInSecs>30</renewalIntervalInSecs>
<durationInSecs>90</durationInSecs>
<registrationTimestamp>1555462894529</registrationTimestamp>
<lastRenewalTimestamp>1555463085849</lastRenewalTimestamp>
<evictionTimestamp>0</evictionTimestamp>
<serviceUpTimestamp>1555462894529</serviceUpTimestamp>
</leaseInfo>
<metadata>
<management.port>8801</management.port>
</metadata>
<homePageUrl>http://localhost:8801/</homePageUrl>
<statusPageUrl>http://localhost:8801/actuator/info</statusPageUrl>
<healthCheckUrl>http://localhost:8801/actuator/health</healthCheckUrl>
<vipAddress>cloudlink-user</vipAddress>
<secureVipAddress>cloudlink-user</secureVipAddress>
<isCoordinatingDiscoveryServer>false</isCoordinatingDiscoveryServer>
<lastUpdatedTimestamp>1555462894530</lastUpdatedTimestamp>
<lastDirtyTimestamp>1555462875800</lastDirtyTimestamp>
<actionType>ADDED</actionType>
</instance>
</application>通过查看这几个Resource类的API不难发现, 真正的逻辑都在一个PeerAwareInstanceRegistry registry中完成
注意区分registry和register
来看下它的继承和实现关系
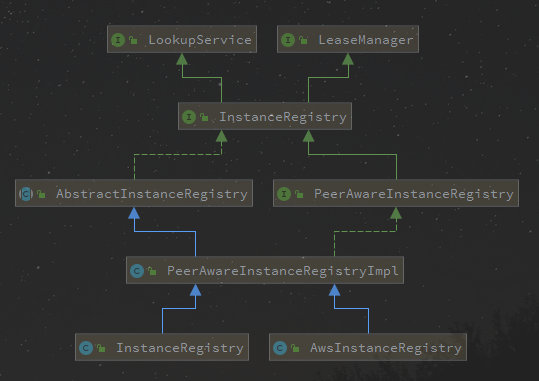
其中LeaseManager中定义了实例注册(register), 续约(renew), 取消(cancel), 剔除(evict)的声明
public interface LeaseManager<T> {
void register(T r, int leaseDuration, boolean isReplication);
boolean cancel(String appName, String id, boolean isReplication);
boolean renew(String appName, String id, boolean isReplication);
void evict();
}进入其中一个实现类, 样子是这样
@Override
public void register(final InstanceInfo info, final boolean isReplication) {
int leaseDuration = Lease.DEFAULT_DURATION_IN_SECS; // 默认90s
if (info.getLeaseInfo() != null && info.getLeaseInfo().getDurationInSecs() > 0) {
leaseDuration = info.getLeaseInfo().getDurationInSecs();
}
super.register(info, leaseDuration, isReplication);
replicateToPeers(Action.Register, info.getAppName(), info.getId(), info, null, isReplication);
}这里做了两件事:
- 调用父类register方法, 传入服务注册所需要的信息(例如服务名, 实例ID等)
- 调用replicateToPeers方法, 拿到所有对等的Eureka Server节点的信息, 把实例的更改信息复制到各节点中, 也就是Peer Replicate过程
这里的leaseDuration对应配置项
eureka.instance.lease-expiration-duration-in-seconds, 默认90s
Registry的流程如下:
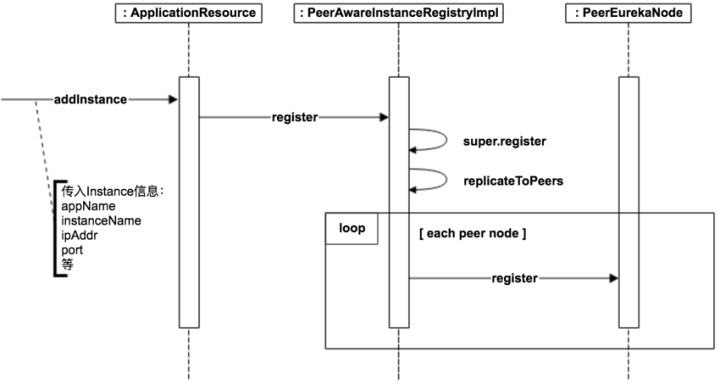
看到这里, 剩下的就是进入父类AbstractInstanceRegistry去查看细节了, 而Renew, Cancel的过程基本都是如此, 不说了
下面对其中一些重点概念进行分析
<br>说明Registry
在LeaseManager中的几个实现中, 都能看到这样一个数据结构
ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>> registry; 如果能区分应用和实例的概念, 那就很好理解这个结构啦
翻译过来就是这样的: Map<应用名, Map<实例名, 实例的信息以及该实例续约相关的时间戳>>
举个例子, 向Eureka Server注册了两个服务server-a, server-b, 其中server-a有两个实例, 端口为8801, 8802
那么registry的结构为
{
"SERVER-A": {
"192.168.153.1:server-a:8802": Lease<InstanceInfo>,
"192.168.153.1:server-a:8801": Lease<InstanceInfo>
},
"SERVER-B": {
"192.168.153.1:server-b:8901": Lease<InstanceInfo>
}
}说明RecentlyChangedQueue
ConcurrentLinkedQueue<RecentlyChangedItem> recentlyChangedQueue;字面翻译是最近改变的队列, 在register, cancel, statusUpdate中, 都能看到对该队列添加了一个租约的变更记录
RecentlyChangedItem中存放了两个属性:
- leaseInfo: 租约
- lastUpdateTime: 上次更新时间
在register中, 还有一个定时任务, 会对该队列定期进行移除
Timer deltaRetentionTimer = new Timer("Eureka-DeltaRetentionTimer", true)
this.deltaRetentionTimer.schedule(getDeltaRetentionTask(),
serverConfig.getDeltaRetentionTimerIntervalInMs(),
serverConfig.getDeltaRetentionTimerIntervalInMs());来看下具体要执行的任务是什么
private TimerTask getDeltaRetentionTask() {
return new TimerTask() {
@Override
public void run() {
Iterator<RecentlyChangedItem> it = recentlyChangedQueue.iterator();
while (it.hasNext()) {
if (it.next().getLastUpdateTime() <
System.currentTimeMillis() - serverConfig.getRetentionTimeInMSInDeltaQueue()) {
it.remove();
} else {
break;
}
}
}
};
}在EurekaServer的配置bean中可以找到上述代码中的两个配置的默认值
// 租约变更的过期时间
private long retentionTimeInMSInDeltaQueue = 3 * MINUTES;
// 移除租约变更记录的定时器的执行间隔时间
private long deltaRetentionTimerIntervalInMs = 30 * 1000;关注if块中的移除条件就好, 也就是说,该任务每30秒执行一次, 移除最后更新时间距离现在超过180秒的租约记录
<br>像不像一个距离为180s的滑动窗口?
Evict
与实例注册, 发送心跳不同的是实例的剔除是Eureka Server主动来做的, 定期剔除无效的服务
-
Server端定期执行剔除任务的默认周期为60s
配置项:
eureka.server.eviction-interval-timer-in-ms -
无效的服务是指未在指定时间内收到心跳(也就是未进行renew汇报的服务)
默认的时间上限为90s, 配置项:
eureka.instance.lease-expiration-duration-in-seconds
代码在这里AbstractInstanceRegistry#evict(), 又是一个定时任务
这点从Eureka Server不停打出的INFO日志也能看出来
[a-EvictionTimer] c.n.e.registry.AbstractInstanceRegistry : Running the evict task with compensationTime 0ms定义如下:
private Timer evictionTimer = new Timer("Eureka-EvictionTimer", true);缓存
ResponseCacheImpl是Eureka Server缓存的实现, 通过读写缓存来降低读写竞争, 增大并发
在服务注册, 下线, 状态改变和剔除失效服务中, 都能看到这样一个方法invalidateCache(), 让什么缓存失效?
涉及到Eureka Server中两个很重要的缓存:
ResponseCacheImpl#readOnlyCacheMapResponseCacheImpl#readWriteCacheMap
从名字也能看出一个只读缓存, 一个读写缓存.
前者是ConcurrentMap, 后者是Guava Cache 它的写失效时间, Load方法都在ResponseCacheImpl的构造函数中定义了
而在invalidateCache()中, 最终操作的都是readWriteCacheMap,
readOnlyCacheMap负责所有客户端读取实例信息的请求, 那么它的值从哪来, 我看到两种方式:
-
方式一: getIfNotExist:
在
ResponseCacheImpl#getValue中可以看到首先会从readOnlyCacheMap读, 如果不存在就从readWriteCacheMap拿, 然后放到readOnlyCacheMap中 -
方式二: Timer
在
ResponseCacheImpl#timer中定义了一个缓存填充的定时器, 在定时器的TaskResponseCacheImpl#getCacheUpdateTask中可以看到会将readWriteCacheMap的内容copy到readOnlyCacheMap
注意这两部分源码中都有一个if判断shouldUseReadOnlyResponseCache, 对应配置项eureka.server.use-read-only-response-cache, 默认为true, 字面翻译很清楚, 相当于开启只读缓存, 不开的话也就没有定时复制的任务了, 直接从读写缓存中拿了
Peer Replicate
对应架构图中Eureka Server之间的Replicate
isReplication
需要注意的是通过查看几个resource API, 都能发现一个放在Header的参数isReplication. 例如
@POST
@Consumes({"application/json", "application/xml"})
public Response addInstance(InstanceInfo info, @HeaderParam(PeerEurekaNode.HEADER_REPLICATION) String isReplication) {}这是因为Eureka Server依赖Eureka Client, 因为Eureka Server也要作为其它Eureka Server的Client,
所以通过isReplication来区分是来自于其它peer的复制请求还是来自普通的client实例的请求,
如果Eureka Server收到属于复制请求的, 就不会再复制给其它Peer, 防止死循环
还需要注意的是在InstanceInfo有一个lastDirtyTimestamp字段, 类似于版本号的概念, 在Peer Replication的过程中会对其进行比较, 在判断数据冲突的情况下, 返回4xx,
让应用实例重新register或同步信息, 来避免复制的冲突问题
前面说过replicateToPeers()的入口点, 这个过程实际是将instance修改信息添加到一个批量任务中打包发送给其他peer
源码参考: com.netflix.eureka.cluster.PeerEurekaNode
里面可以看到创建Batch Task的过程, 由于是异步, 所以并不能保证在服务实例状态发生变更时, 所有Peer上的信息都一致.
<br>Eureka Server端采用的是P2P的复制模式, 但是它不保证复制一定成功, 因此还通过与Eureka Client定期进行hearbeat, Server端内部的矫正机制来做应用实例信息的数据修复, 尽力提供一个最终一致性的服务实例视图
Eureka Client
通过以上Eureka Server中的, 基本对架构图中的Register, Renew, Cancel过程有了基本的认识
再来简单说说Eureka Client
<br>provider
对于Client端的Provider来说, 在启动和实例状态变化是, 需要通知Server端
源码参考(有序):
com.netflix.discovery.InstanceInfoReplicator#onDemandUpdatecom.netflix.discovery.DiscoveryClient#registercom.netflix.discovery.shared.transport.decorator.EurekaHttpClientDecorator#registercom.netflix.discovery.shared.transport.jersey.AbstractJerseyEurekaHttpClient#register
流程图如下:
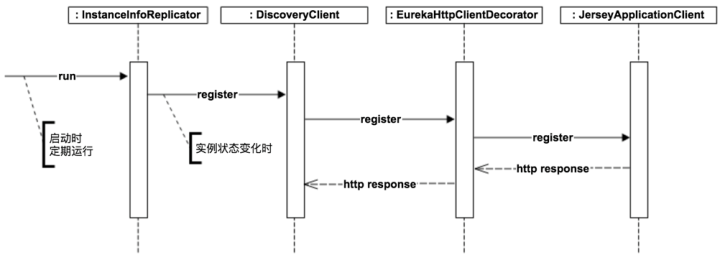
同样, Renew, Cancel的过程也参照这个顺序
<br>Consumer
对于Client端的Consumer来说, 需要拉取服务实例的列表并缓存, 还需要定期更新
流程如下图
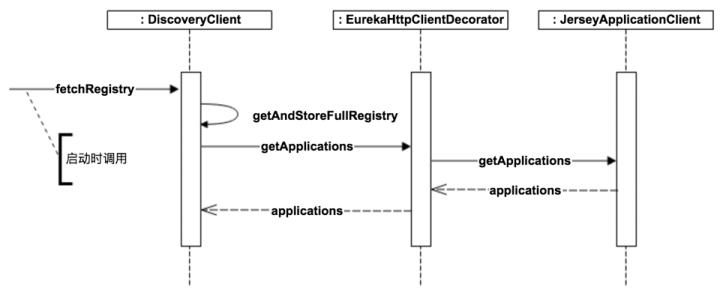
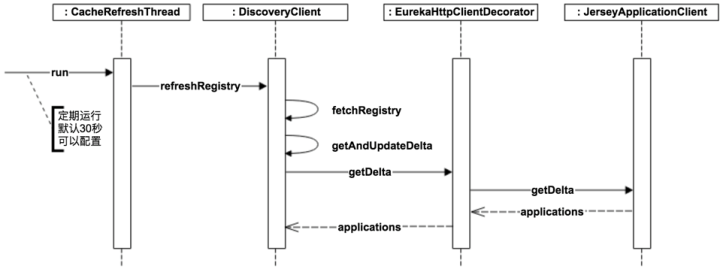
总结
Netflix Eureka是典型的注册中心+嵌入式客户端架构, 并且各节点之间对等
通过上面的分析, 对Netflix Eureka架构图中的各个过程都有了一定的了解, 以及一些配置项的细节
能够发现的一点是, 无论 Eureka Server 之间 Peer-to-Peer 的 Replicate 过程, 还是 Eureka Client 向 Eureka Server 发起 Get Service Registries 的过程
实现中看到了大量的 schedule、cache、异步过程, 以及 Eureka 的自我保护机制, 这种模型简化了集群管理的复杂度, 易于实现高可扩展性.
但是并不能完全保证强一致, 而是最终一致性.
刚刚接触Eureka的新手肯定能够发现, 为什么在服务上线/下线后, 注册中心并没有立刻感知到, 而是间隔了若干时间.
这在很多业务场景下是能够满足的, 因为作为Eureka客户端来说, 通常都会配置Ribbon提供失败重试, 尤其对于服务发现这一场景, 即使返回了非最新的服务供消费者调用, 也比什么都不返回好
也就是 Eureka! Why You Shouldn’t Use ZooKeeper for Service Discovery
可参考中文翻译: https://blog.csdn.net/jenny8080/article/details/52448403
这也是 Eureka 与其它几个服务发现组件(Zookeeper, Etcd, Consul)显著的区别. 在 CAP 理论中, Eureka 保证 AP, 其它几个保证 CP